
Eviter le sur-apprentissage en machine learning
Groupe Biopuces
February 29, 2024
Modèle descriptif VS modèle prédictif
Analyse prédictive
Construire un modèle pour catégoriser (prédire) sur un individu une caractéristique inconnue.

Qu’est-ce que le surapprentissage ?

Objectif : séparer ce qui est de la tendance et ce qui est du bruit.
Qu’est-ce que le surapprentissage ?

plus de biais, moins de variance
plus de variance, moins de biais
On cherche le modèle le plus simple qui donne les meilleurs résultats.
Processus général de machine learning

Processus général de machine learning

Processus général de machine learning

Classiquement 60%/40%, 70%/30% ou 80%/20%.
train : l’échantillon sur lequel on va ajuster le modèle.
test : l’échantillon sur lequel on va vérifier que le modèle s’applique bien à un autre jeu de données.
Processus général de machine learning

L’échantillon test ne doit JAMAIS être utilisé pendant la phase d’entraînement
N’empêche pas le sur-apprentissage !
Processus général de machine learning

L’échantillon de validation va nous servir à valider le modèle, pendant la phase d’entraînement.
N’empêche toujours pas le sur-apprentissage !
Processus général de machine learning
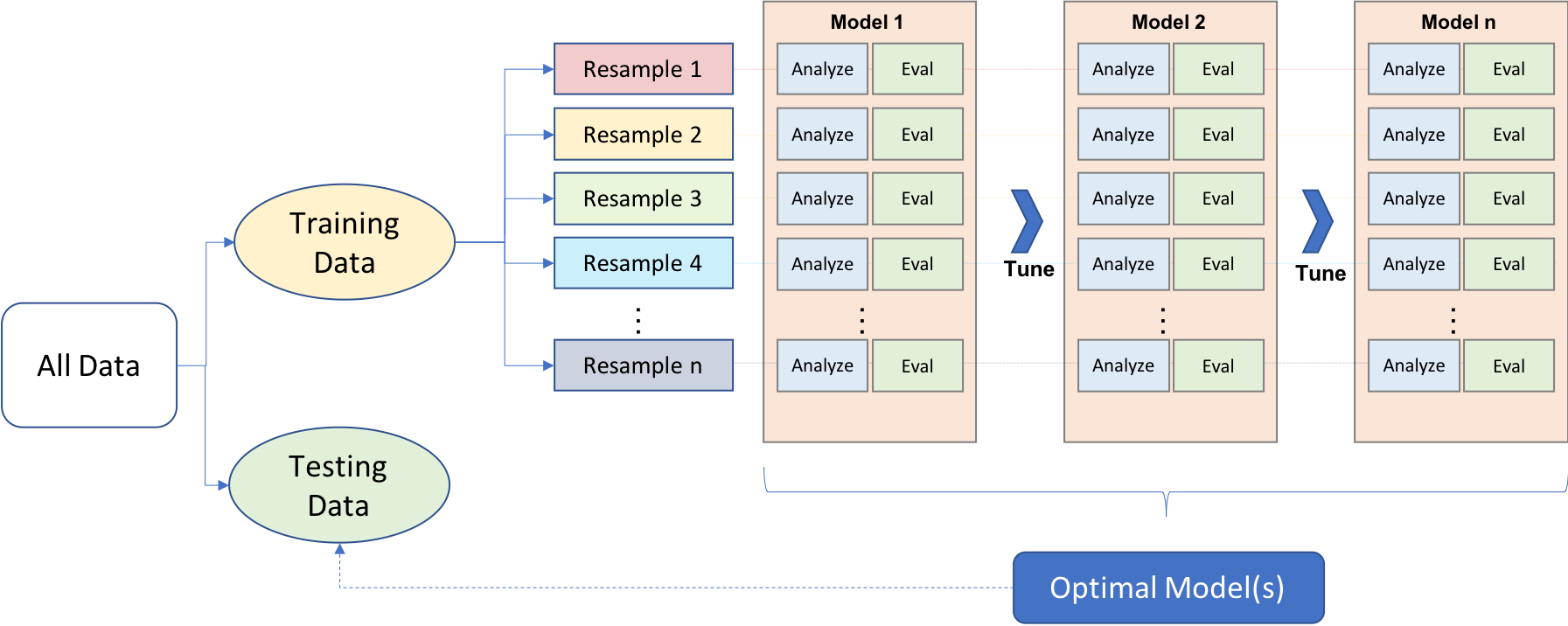
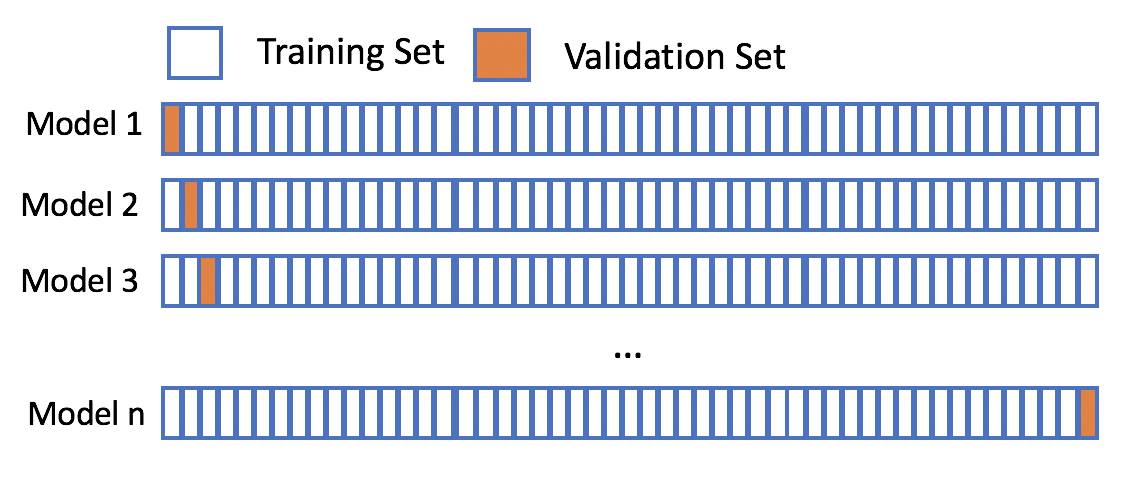
Validation croisée exemple k-fold

Déséquilibre des classes
Exemple dans un problème de classification on essaie de prédire Y qui est distribué 1: 5% et 0: 95%.

Déséquilibre des classes - Rééchantillonnage de la phase d’entrainement

Déséquilibre des classes - Rééchantillonnage de la phase d’entrainement

Déséquilibre des classes - Rééchantillonnage de la phase d’entrainement

Selon les modèles on n’est pas obligé d’avoir 50/50. Ex. Arbres : 5/10% peuvent suffire.
Peu d’observations
Risque aigu.

Peu d’observations - LOOCV
Peu d’observations
- Utiliser des approches ensemblistes (combiner plusieurs modèles - bagging, boosting, stacking, …) pour diminuer la variance.

Peu d’observations
- Utiliser des approches ensemblistes (combiner plusieurs modèles) pour diminuer la variance.

Hyperparamètres - Optimisation

Trouver un compromis entre biais et variance.
Processus général de machine learning
Références

Boehmke, Brad, and Brandon M Greenwell. 2019. Hands-on Machine Learning with r. CRC press.
Chawla, Nitesh V, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. 2002. “SMOTE: Synthetic Minority over-Sampling Technique.” Journal of Artificial Intelligence Research 16: 321–57.
Hawkins, Douglas, Subhash Basak, and Denise Mills. 2003. “Assessing Model Fit by Cross-Validation.” Journal of Chemical Information and Computer Sciences 43 (March): 579–86. https://doi.org/10.1021/ci025626i.
Menardi, Giovanna, and Nicola Torelli. 2014. “Training and Assessing Classification Rules with Imbalanced Data.” Data Mining and Knowledge Discovery 28: 92–122.
Molinaro, Annette M., Richard Simon, and Ruth M. Pfeiffer. 2005. “Prediction error estimation: a comparison of resampling methods.” Bioinformatics 21 (15): 3301–7. https://doi.org/10.1093/bioinformatics/bti499.
Comment diviser les données ?
Pour la division train/test :
Simple tirage aléatoire
On va tirer aléatoirement 30% (ou 20% ou 40%) des données totales pour former l’échantillon test. Le reste formera l’échantillon d’apprentissage.
Tirage aléatoire stratifié
On veut que la distribution de la variable à expliquer (cible) soit la même dans les échantillons. Le tirage se fait soit par quantile (var. continue) soit par classe (var. catégorielle). Parfois utile par exemple dans des distributions déséquilibrées.
Dans tous les cas toujours fixer une graine pour pouvoir reproduire le tirage (par ex. en R :
set.seed()`).